视频服务
由于多模态大模型具备除语言能力以外的图片,视频理解能力 ,原有的传统的纯图像推理和单一逻辑判断
的系统方案将逐渐由基于大模型的推理方案所取代.一方面在于新的基于大模型的方案将更加简单,极大的
降低了开发任务的复杂度,另一方面在于大模型具有先验知识和场景理解能力以及逻辑推理能力,其事件
判断的准确率也大大的增强.
本视频服务正是基于大模型进行设计,核心理念基于六边型架构,除了原有的拉流解码,重点则围绕大模型
的提示词结合视觉输入,模型推理以及结果解析形成基本的任务Chain,然后将正确的推理结果进行存储和
入库.为后续系统提供数据来源.
类视图
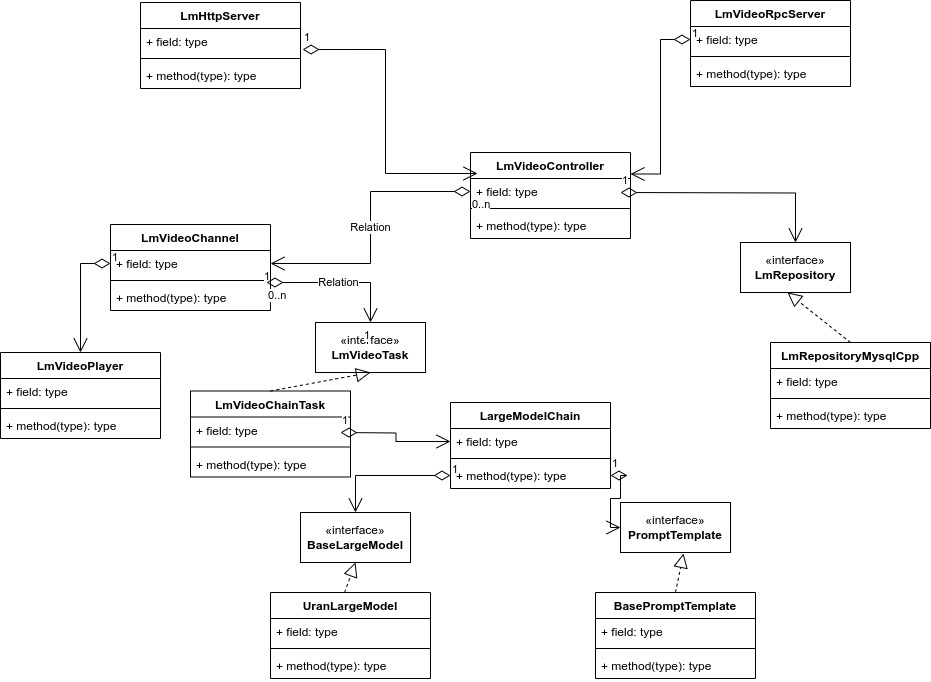
类职责说明:
LmHttpServer: HTTP + JSON的的入站服务,对外暴露创建任务和删除任务接口
LmVideoRpcServer: RPC的入站服务器,对外暴露与http用样功能的接口
LmVideoController: 任务流转的控制器,负责相关任务的创建,组装,数据回调入库等
LmVideoChannel: 视频通道,对同一视频源启动拉流解码,并管理和分派任务
LmVideoPlayer: 根据url进行拉流解码
LmVideoChainTask(LmVideoTask): 视频任务,通过调用大模型任务链完成推理,解析结果并回调数据
LargeModelChain: 多模态任务推理执行链,包括组合提示词和模型推理
UranLargeModel(BaseLargeModel): 大模型推理适配接口,对不同的模型服务进行统一接口适配
BasePromptTemplate(PromptTemplate): 提示词模板,根据不同的任务需求结合提示词,用户输入生成待推理消息
LmRepositoryMsqlCpp(LmRepository): 数据仓库接口Msql版本的实现,作为数据的出站适配器
时序图
启动任务分为两步
第一步创建任务,通过传入正确的参数,如视频url,任务名称等
第二步视频解析,任务创建并启动以后自动拉流解码,持续推理解析视频
创建任务
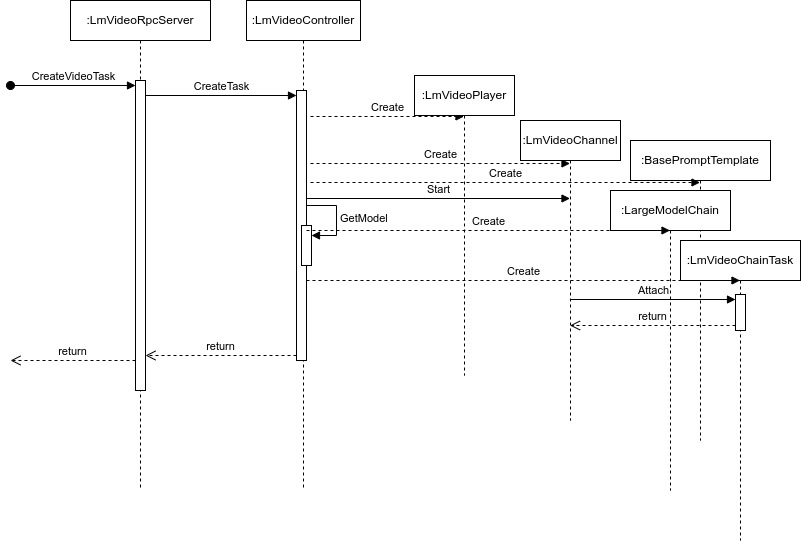
流程说明:
1,用户侧通过传递正确的参数调用LmVideoRpcServer的CreateVideoTask进行任务启动
2.LmVideoRpcServer调用LmVideoController的CreateTask函数完成整个任务的创建
3.在任务创建的过程中,除了创建LmVideoPlayer, LmVideoChannel, LargModelChain, LmVideoChainTask
等一系列的对象以外,同时要调用LmVideoChannel的Start函数启动拉流解码,以及LmVideoChannel的
Attach函数将LmVideoChainTask绑定到该Channel以结合特定的提示词完成特定的推理任务.
视频分析
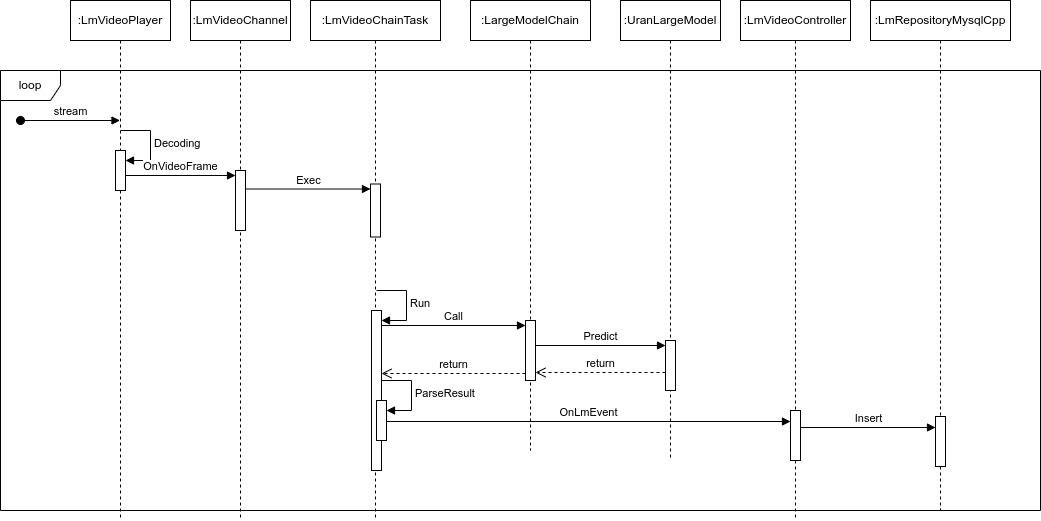
流程说明:
1.在任务创建后,LmVideoPlayer就开始拉流解码,将解码后的图片通过OnVideoFrame回调到LmVideoChannel
2.LmVideoChannel将图片进行格式转换后同步到内存中,然后调用所有Attach的LmVideoChainTask的Exec完成任务分派
3.每个LmVideoChainTask异步调用LargeModelChain的Call方法进行推理.LargeModelChain会结合之前绑定的提示词
构建推理参数,调用UranLargeModel进行推理.
4.LmVideoChainTask 在结果返回后ParseResult解析模型推理结果.如果有事件发生则调用LmVideoController的OnLmEvent
进行回调
5.LmVideoController通过LmRepositoryMysqlCpp的Insert接口完成事件入库和图片保存.
提示词
根据图片内容,回答以下问题,
使用 json 格式回答,确保你的回答是必须是正确的 json 格式,并且能被 python 语言的 `json.loads` 库解析, 格式如下:
[
{
"event":"动物闯入",
"question":"图片里面有动物吗",
"answer":"no",
"reason":"从图片里面看出,画面中没有动物。"
}
...
]
用户问题:
动物闯入: 图片里面有动物吗, 请回答'yes'或者'no', 并给出动物数量
车辆拥堵: 图片里是否有车辆拥堵发生, 请回答'yes'或者'no', 并且给出拥堵时的车辆数量
车辆数: 图片里面有车辆吗, 请回答'yes'或者'no', 并给出车辆数量