检索增强(RAG)
检索增强中最大的难点和问题在于文档的简单分段拆分后Embedding存储,
原始问题直接Embedding在检索过程中召回精度低,并且遗漏高, 特别是在问题存在多知识点的情况下
本方案重点引入了传统的NLP方法通过多关键词/主题词提取与检索提升问题搜索的召回率.
整体架构
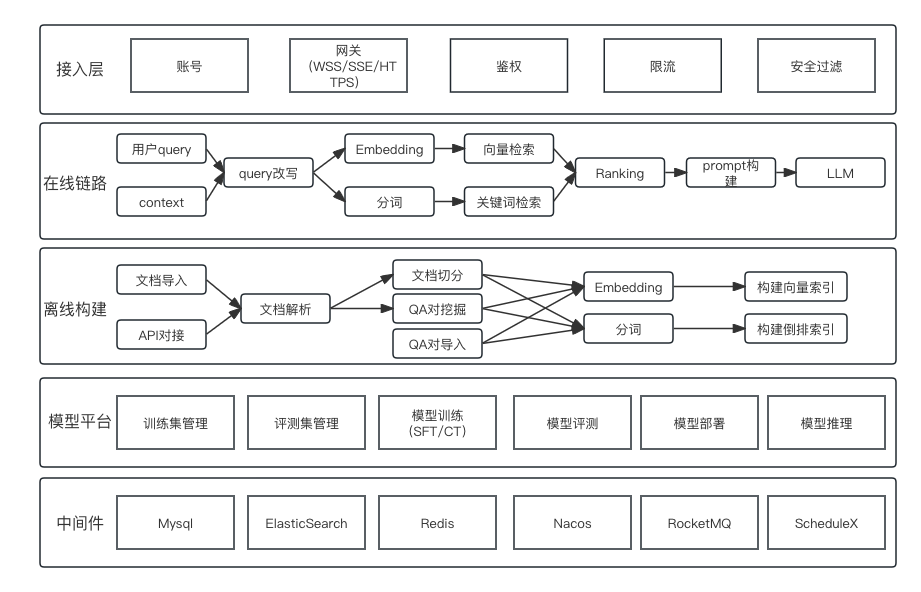
体系结构
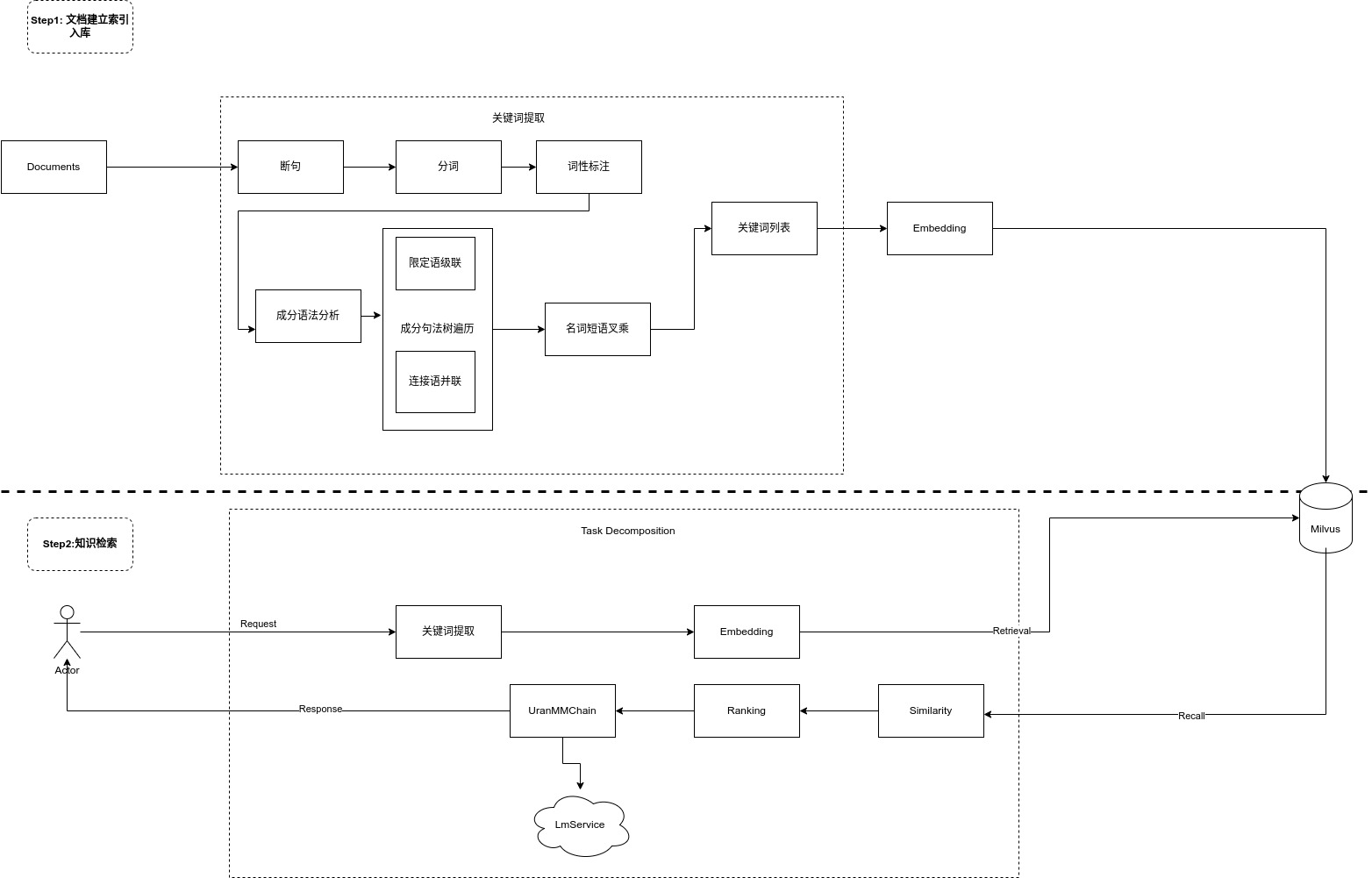
工作流程
主要的工作流程分两大步骤:
1.文档处理,解析,生成关键词表.Embedding,入库
2. 用户查询,问题解析,生成关键词列表,Emebedding, 相似度比对,提取TopK,大模型问题和内容整合,返回
Step1: 建立文档索引
- 基于传统 NLP 的成分句法分析,提取名词短语;再通过短语间的依存关系,生成关键词列表
- 关键词提取的大致流程:
- 短句->分词->词性标注->成分语法分析->[限定语级联, 连接语并联]->名词短语叉乘->关键词列表
- 从完整语句的 Embedding,切换为关键词 Embedding:
- 知识库构建时。基于单知识点入库,入库时提取关键词列表进行 Embedding,用于检索。
Step2: 用户搜索
- 首先对用户的问题提取关键词列表, 然后进行 Embedding
- 将搜索结果相似度TopK后去掉不符合阈值的留下多条满足条件的记录
- 将召回的多条记录通过UranMMChain提交给 LLM 整合后返回
该方案的优势在于:
- 相比传统 Embedding,大幅提升召回精准度。
- 支持单次交互,对多知识点进行聚合处理。而不必让用户,手动分别查询单个知识点,然后让 LLM 对会话历史中的单个知识点进行汇总。
- 使用传统 NLP 在专项问题处理上,相比 LLM 提供更好的精度和性能。
- 相对于HyDE(虚构文档-依靠大模型对多知识点拆分问题意图)方案减少了对 LLM 的交互频次;提升了交付给 LLM 的有效信息密度;大大提升问答系统的交互速度。
补充-多知识点的问题:
多知识点聚合处理场景下,Embedding-Search 召回精度较低 的问题。典型应用范式是:
- 一个仓库有 N 条记录,每个记录有 M 个属性;
- 用户希望对 x 条记录的y 个属性进行查询、对比、统计等处理。
这种场景在游戏攻略问答中很常见,以体育游戏 NBA2K Online2 为例:
多知识点——简单查询
Q: 皮蓬、英格利什和布兰德的身高、体重各是多少?
多知识点——筛选过滤
Q: 皮蓬、英格利什和布兰德谁的第一位置是 PF?
多知识点——求最值
Q: 皮蓬、英格利什和布兰德谁的金徽章数最多?
参考资料
https://zhuanlan.zhihu.com/p/642125832
https://luxiangdong.com/2023/10/07/ragfusion/#/%E5%B7%A5%E5%85%B7%E5%92%8C%E6%8A%80%E6%9C%AF%E6%A0%88
https://luxiangdong.com/2023/10/27/rag10/#/%E5%BC%95%E7%94%A8
https://luxiangdong.com/2023/11/06/rerank-ev/#/%E6%95%B4%E4%BD%93%E4%BC%98%E5%8A%BF
强烈建议阅读 https://zhuanlan.zhihu.com/p/665383403
现在越来越多的实践者开始意识到一套向量数据库打天下的方案已经不够了,于是有了各种花式疗法,从构建索引到回复生成,可谓百花齐放,眼花缭乱:
- 内容切片不够好,容易切碎,于是有了段落智能划分;
- 向量生成的质量不可控,于是有了可根据不同QA场景动态生成向量的Instructor;
- 隐式的动态向量不够过瘾,再用HyDE做个中间层:先生成一些虚拟文档/假设文档再做召回,提升召回率;
- 如果向量这一路召回不够,再上关键词召回,传统BM25+向量HNSW融合各召回通路;
- 召回的太多容易干扰答案生成,探究一下Lost in the Middle,搞一搞trick,或者用LLMLingua压缩;
- 嫌召回太麻烦?直接扩到100k窗口全量怼进大模型,LongLoRA横空出世;
- 刚才提到的各个环节需要改进的点太多,懒得手工做,直接交给大模型,用Self-RAG替你完成每个步骤……